
Ce projet page visait à décrire les préconisations de décommissionnement de la plate-forme Google Cloud Platform en vue de l’intégration des applications sur la plate-forme maintenue par l’équipe Système et Réseau d’APF France handicap.

L’idée est de rationaliser les environnements au sein d’une architecture facilement manipulable, supervisée et administrée par les équipes interne tout en prévoyant une montée en compétence et la formation pour les équipes concernées (prestataires de développement, équipe Système et Réseau).
Objectifs
Analyse de l’existant
- Environnements (production, tests, recette, intégration, développement)
- Méthodologie (développement, intégration, déploiement)
- Outils (IDE, exploitation, supervision, sauvegarde, monitoring)
- Risques (compétences, responsabilités, suivi, maintenabilité, performance)
Le contexte du projet faisait état d’un constat suite à une réorganisation et à l’externalisation des développements vers des prestataires :
- 2 Hébergeurs (Interne & Google Cloud)
- Compétences réparties entre 2 équipes (Développement & Système et Réseaux)
- Lien d’interconnexion restreint (Accès depuis Google aux serveurs TDF via VPN)
- Besoin d’alignement de la sécurité et de la responsabilité d’administration
- Réduction de coût d’hébergement
- Refonte de l’architecture
Voici un schéma de la plate-forme suite à l’analyse de l’existant :
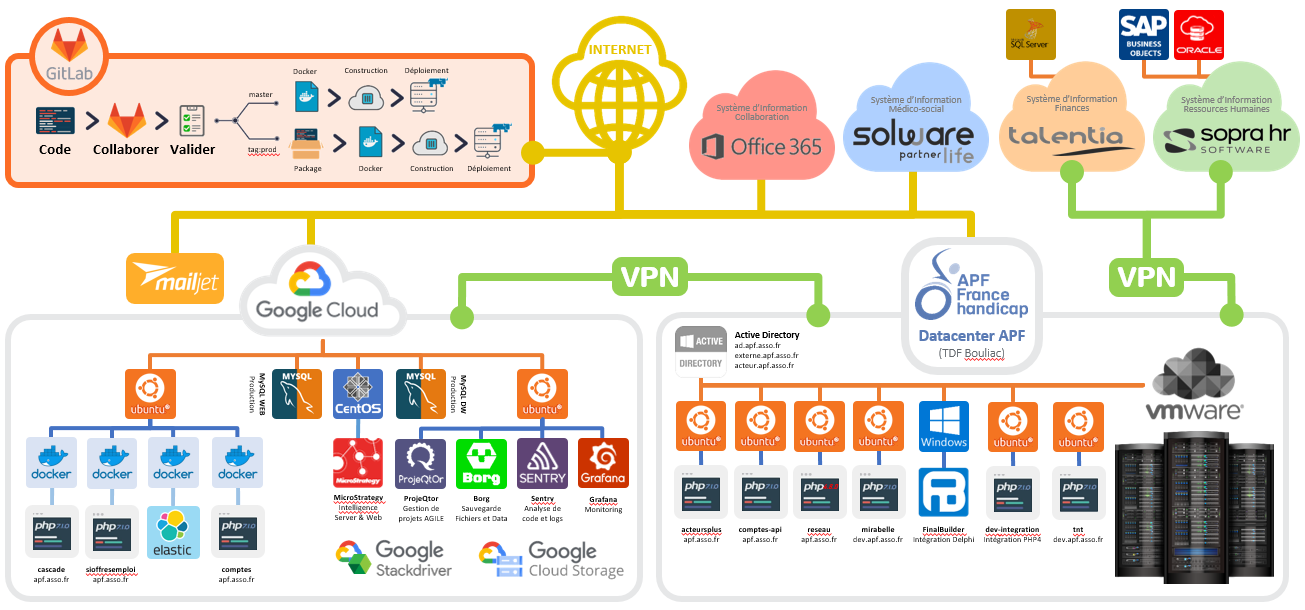
Cette architecture hybride inclut des environnements installés sur des machines virtuelles (DataCenter TDF) et d’autres exécutés à travers des conteneurs Docker.
Cible d’architecture
J’ai été en charge de la définition d’une architecture cible en tenant compte de la montée en compétence des développeurs pour garantir un déploiement automatisé utilisant Docker, Gitlab CI/CD ainsi que celle des administrateurs Système et Réseaux pour la mise en place et la maintenance de la plate-forme.
L’idée globale est de rationaliser toutes les applications et les outils sur un seul datacenter en utilisant une infrastructure flexible et facilement maintenable notamment sur les versions des systèmes d’exploitation.
Voici un schéma de l’architecture visée :
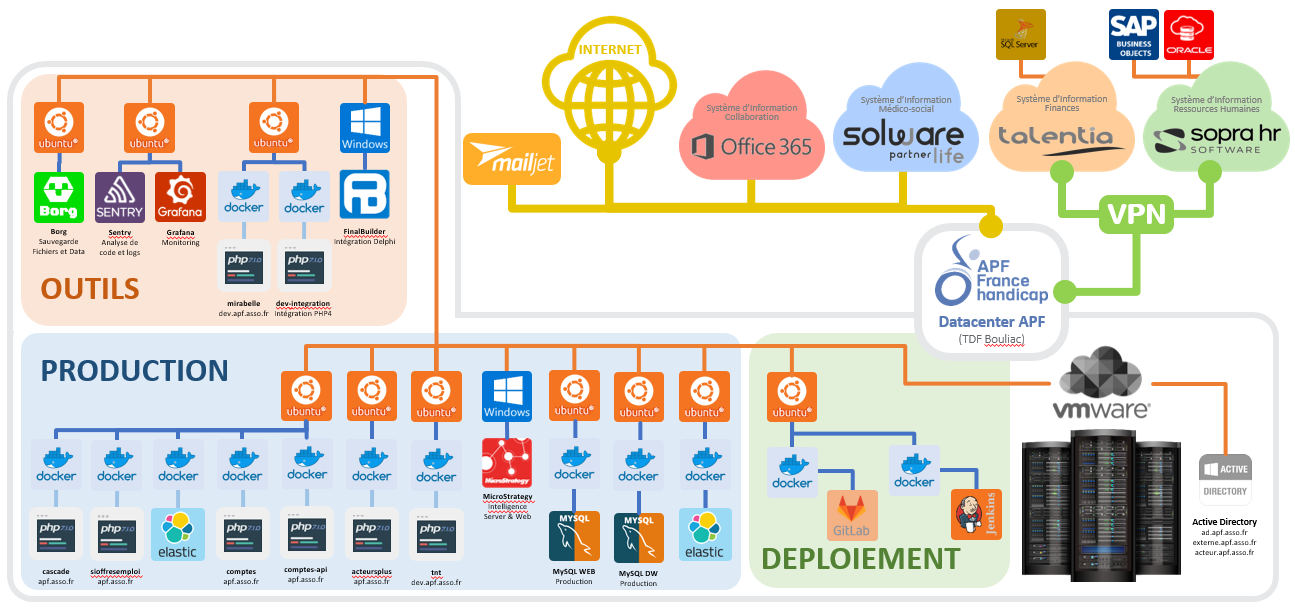
Par soucis de flexibilité, cette infrastructure peut reposer sur des environnements virtuelles installées sous Linux ou sous Windows (en utilisant la technologie WSL). Les préconisations feront l’objet de façon optionnelle de l’utilisation de Kubernetes pour rendre scalable l’exécution des environnements au sein d’un cluster de conteneurs.
Technologies proposées
Une description des technologies proposées pour la production, la recette, l’outillage et le déploiement sera décrit dans cette section.
L’environnement de production est basée en majorité sur la technologie Docker. Docker permet de créer des conteneurs pour garantir l’intégrité de l’environnement d’exécution d’une application. Ces conteneurs sont lancé à partir d’image décrite dans des fichiers de configuration qui permet de maitriser sa composition sous forme de commande et de fichier. Le déploiement est réalisé au moyen de commande spécifique à Docker. Dans le cadre d’une application utilisant plusieurs images (simulant plusieurs serveurs applicatifs), il est possible de décrire l’orchestration de ces conteneurs avec Docker Compose au moyen d’un fichier de configuration au format YAML.
Etant donné que toute la configuration (Docker et Docker Compose) est réalisé dans des fichiers, ils peuvent être intégré au gestionnaire de source de l’application. La variabilité des configurations (production, recette et développement) peut être réalisée avec des fichiers ENV.
Docker
Une image Docker est configurée au moyen d’un fichier Dockerfile. La première instruction FROM permet de déterminer à partir de quelle image (du registry publique hub.docker.com ou d’un registry privé) est basé l’image du fichier.
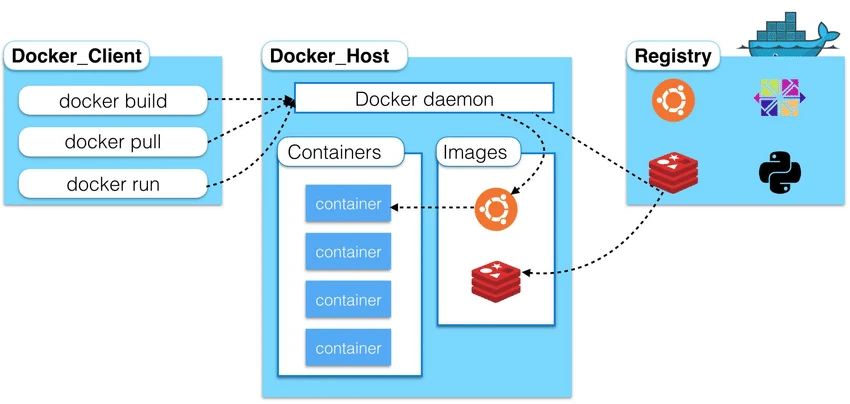
Ci dessous un schéma explicatif simplifier des étapes de construction et de déploiement d’un conteneur à partir d’une image héritée de celle hébergée sur une registry :Open High-level-overview-of-Docker-architecture.png
Voici un exemple d’une image docker à partir d’une distribution ubuntu dont on installe curl :
FROM ubuntu:22.04 RUN apt-get update RUN apt-get install -y curlLes principales instructions en ligne de commande utilisables dans le répertoire contenant le fichier Dockerfile sont les suivantes.
docker build
docker buildCette instruction va récupérer l’image ubuntu avec le tag 22.04 en local puis lancer un conteneur à partir de cette image et exécuter les instructions du fichier Dockerfile puis sauvegarder sont état dans une nouvelle image dans le registre local.
docker images
On pourra retrouver les images téléchargées et construites localement en utilisant la commande :
docker imagesdocker pull <image>
Pour mettre à jour une image à partir d’un registry, il est possible d’utiliser la commande :
docker pull <image>:<tag>docker run
Pour créer un conteneur, il suffit d’utilisation la commande :
docker run --rm -it <image>:<tag> <command>Les paramètres de la commande utilisée sont les suivants :
- –rm : suppression du conteneur une fois que celui ci est arrêté
- -it : permet de récupérer dans la console actuelle la console du conteneur en mode attachée
- <image> : image à utiliser (sera téléchargée si elle n’est pas présente localement)
- <tag> : tag de l’image à utiliser
- <command> : commande à lancer à l’intérieur du conteneur
Voici un schema représentant les commandes principales utiliser avec Docker :
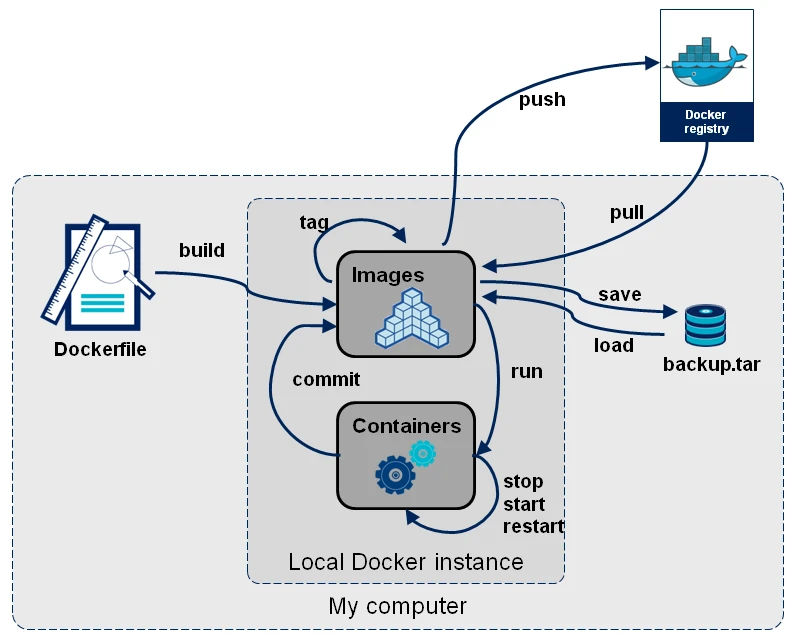
La documentation concernant l’utilisation de Docker est disponible à l’adresse https://docs.docker.com/
Pour se familiariser avec Docker, il est possible de suivre les tutoriels de Xavki sur Docker disponibles à l’adresse https://xavki.blog/docker-tutoriaux-francais/
Docker Compose
Dans le cadre de l’utilisation pour une application composer de plusieurs composants, il est plus flexible d’utiliser plusieurs conteneurs reliés entre eux au sein d’un stack. C’est ce que propose Docker Compose. Il est configurable au moyen d’un fichier de configuration au format YAML nommé par défault docker-compose.yml.
Voici un schéma d’une stack utilisant des conteneurs intégrant nginx, PHP, redis, mariadb et composer et un conteneur intégrant le proxy traefik :
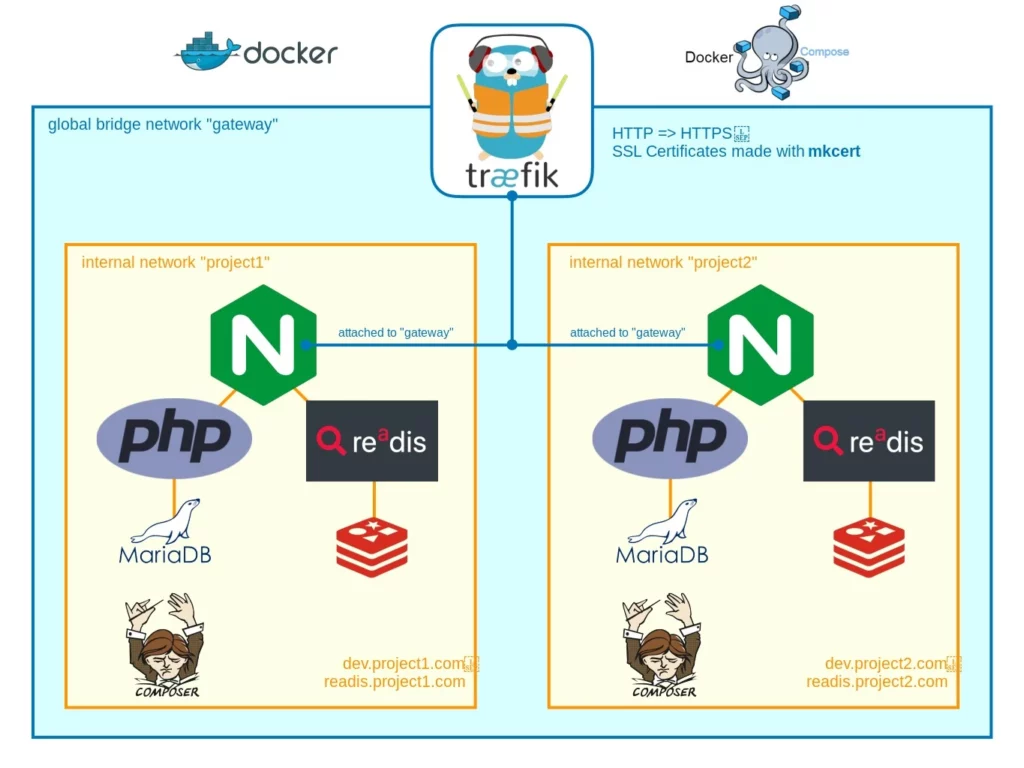
Voici un exemple docker-compose.yml :
version: '3'
services:
db:
image: mariadb
volumes:
- ./mysql_data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_USER: hirsute
MYSQL_PASSWORD: password
MYSQL_DATABASE: hirsute_db
ports:
- "3306:3306"
web:
build: ./Dockerfile
ports:
- "80:80"
volumes:
- ./html:/var/www/htmlCe fichier permet de lancer une stack de 2 conteneurs dont l’un est basé sur une image mariadb (par défaut, si aucun tag n’est présent, il utilise latest) et l’autre sur une image dont la description est faite dans le fichier Dockerfile.
Le conteneur db contient un répertoire /var/lib/mysql dont les fichiers qu’il contient seront liés avec ceux du répertoire mysql du répertoire courant. Le conteneur web contient un répertoire /var/www/html dont les fichiers qu’il contient seront liés avec ceux du répertoire html du répertoire courant.
L’instruction port var rediriger les ports spécifés de l’hôte vers ceux des conteneurs (3306 pour le service db et 80 pour le service web).
Les principales instructions en ligne de commande utilisables dans le répertoire contenant le fichier docker-compose.yml sont les suivantes.
docker compose build
docker compose buildCette instruction va construire toutes les images spécifiées dans le fichier de configuration docker-compose.yml en local.
docker compose up
Cette instruction va procéder au lancement des conteneurs décrit dans le fichier docker-compose.yml. Par défaut les conteneurs seront préfixés par le nom du répertoire courant. Un réseau Docker spécifique sera créé pour relier les conteneurs de la stack entre eux.
docker compose updocker compose down
Cette instruction va arrêter les conteneurs puis les supprimer et supprimer le (ou les réseaux) spécifiques à la stack.
docker compose downdocker compose pull
Cette instruction va mettre à jour sur le repository local à partir des repository distant les images utilisés par les conteneurs du fichier docker-compose.yml.
docker run --rm -it <image>:<tag> <command>La documentation concernant l’utilisation de Docker Compose est disponible à l’adresse https://docs.docker.com/compose/
Pour se familiariser avec Docker, il est possible de suivre les tutoriels de Xavki sur Docker disponibles à l’adresse https://xavki.blog/docker-compose-tutoriaux-francais/
Gitlab
GitLab est une plateforme de développement collaborative open source éditée par la société américaine du même nom. Elle couvre l’ensemble des étapes du DevOps. Se basant sur les fonctionnalités du logiciel Git, elle permet de piloter des dépôts de code source et de gérer leurs différentes versions. Son usage est particulièrement indiqué pour les développeurs qui souhaitent disposer d’un outil réactif et accessible.
L’interface de GitLab reste très similaire à celle de GitHub. Toutefois, GitLab propose des options pour le moins pratiques :
- Gestion de projet
- Planification / priorisation
- Build
- Test logiciel
- Sécurité applicative
- Gestion des configurations
- Monitoring
- Intégration et déploiement continus, etc.
La documentation concernant l’utilisation de Gitlab est disponible à l’adresse https://docs.gitlab.com/
Pour se familiariser avec Gitlab CI, il est possible de suivre les tutoriels de Xavki disponibles à l’adresse https://www.youtube.com/playlist?list=PLn6POgpklwWrRoZZXv0xf71mvT4E0QDOF
Subversion
Subversion est un système optimiste d’archivage (versionnage) et de partage de fichiers entre utilisateurs. Subversion autorise plus d’une personne à modifier un même fichier en même temps. Ce système suppose que les conflits de modifications sont rares. Si deux utilisateurs du dépôt modifient des parties non-communes d’un fichier, les outils optimistes fusionnent tout simplement les modifications. Inversement, dans le cas de modifications conflictuelles, le conflit doit être résolu manuellement.
Subversion est un système à dépôt centralisé. Un dépôt (ou référenciel) représente un point unique auquel les utilisateurs s’adressent pour obtenir, ajouter ou mettre à jour fichiers et dossiers. On peut appeler cet endroit de référence la copie officielle. Chaque utilisateur du dépôt possède ensuite une copie locale du référentiel commun. Comme un utilisateur fait ses modifications sur sa copie locale, la copie officielle distante n’est pas changée automatiquement. Pour partager ses modifications, il doit les soumettre au dépôt. Par la suite, ses collègues, qui veulent obtenir la version plus récente, doivent, à leur tour, mettre à jour leur copie locale.
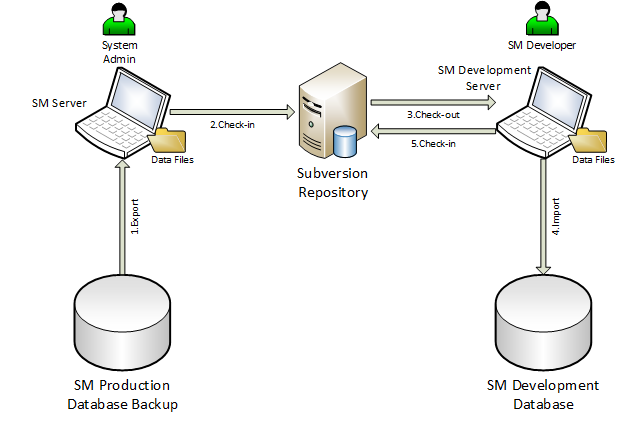
Subversion est utilisé pour les anciens projets. L’objectif est donc de migrer les projets encore en exploitation en production sous Gitlab et de gérer les déploiement avec Gitlab CI pour garantir leur intégrité.
GitLab CI
GitLab CI/CD est un outil de GitLab conçu pour gérer l’intégration et le déploiement en continu de code et révisions applicatives. GitLab CI/CD passe par la configuration d’un fichier baptisé .gitlab-ci.yml placé dans le répertoire root. Un fichier qui génère un pipeline exécutant les changements de code au sein du dépôt de code.
GitLab Runner
Gitlab-runner est l’application permettant d’exécuter des tâches dans un pipeline GitLab CI/CD. En cas d’installation de Gitlab-runner en local, il est conseillé de le déployer sur une machine distincte de celle qui héberge l’instance GitLab, à la fois pour des raisons de performance et de sécurité. Chacune devra être équipées de sa propre pile logicielle : OS, Kubernetes, Docker…
Exemple de script CI/CD de Gitlab
Pour que la CI/CD sur GitLab fonctionne il vous faut un manifeste .gitlab-ci.yml à la racine de votre projet. Dans ce manifeste vous allez pouvoir définir des stages, des jobs, des variables, des anchors, etc.
On peut lui donner un autre nom mais il faudra changer le nom du manifeste dans les paramètres de l’interface web.
Dans le manifeste de GitLab CI/CD vous pouvez définir un nombre illimité de jobs, avec des contraintes indiquant quand ils doivent être exécutés ou non.
Voici comment déclarer un job le plus simplement possible :
job:1:
script: echo 'my first job'
job:2:
script: echo 'my second job'Il est possible de configurer une image Docker à utiliser pour réaliser les actions des jobs avec une simple déclaration dans le manifeste (il faut que le runner soit configuré sous Docker) :
image: alpine # Image utilisée par tous les `jobs`, ce sera l'image par défaut
job:node: # Job utilisant l'image node
image: node
script: yarn install
job:alpine: # Job utilisant l'image par défaut
script: echo $USERIl est également possible de définir des étapes de réalisation au moyen des stages. Cette déclaration permet de grouper des jobs en étapes. Par exemple on peut faire une étape de build, de codestyling, de test, de code coverage, de deployment, …
stages: # Ici on déclare toutes nos étapes
- build
- test
- deploy
job:build:
stage: build # On déclare que ce `job` fait partie de l'étape build
script: make build
job:test:unit:
stage: test # On déclare que ce `job` fait partie de l'étape test
script: make test-unit
job:test:functional:
stage: test # On déclare que ce `job` fait partie de l'étape test
script: make test-functional
job:deploy:
stage: deploy # On déclare que ce `job` fait partie de l'étape deploy
script: make deploy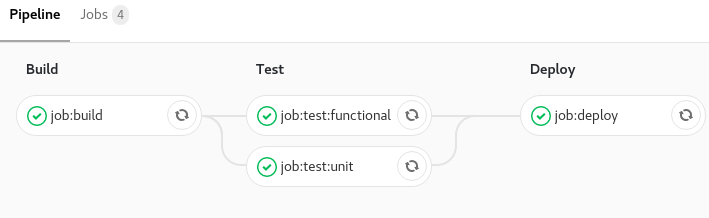
Les jobs peuvent être configurés pour être lancé manuellement (avec un bouton dans l’interface de Gitlab) ou bien sur des évènements (temporels ou de changement de code source).
Des exemples de configuration du manifeste sont disponible sur cette page : Blog Eleven Labs – Introduction à Gitlab CI/CD (eleven-labs.com)
La documentation concernant l’utilisation de Gitlab CI est disponible à l’adresse https://docs.gitlab.com/ee/ci/
Pour se familiariser avec Gitlab CI, il est possible de suivre les tutoriels de Xavki disponibles à l’adresse https://www.youtube.com/playlist?list=PLn6POgpklwWrRoZZXv0xf71mvT4E0QDOF
Outils proposés
SonarQube : Qualité de code source

SonarQube est un logiciel libre de qualimétrie en continu de code. Il aide à la détection, la classification et la résolution de défaut dans le code source, permet d’identifier les duplications de code, de mesurer le niveau de documentation et connaître la couverture de test déployée.
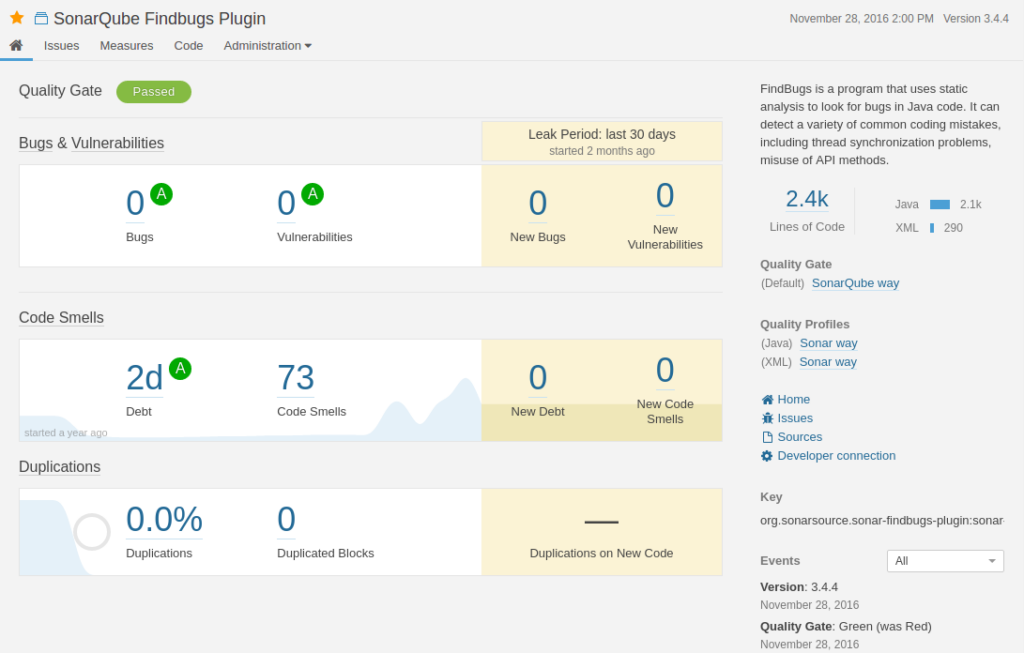
SonarQube permet une surveillance continue de la qualité du code grâce à son interface web permettant de voir les défauts de l’ensemble du code et ceux ajoutés par la nouvelle version. Le logiciel peut être interfacé avec un système d’automatisation comme Jenkins pour inclure l’analyse comme une extension du développement.
Il est possible d’intégrer les étapes de validation de code par SonarQube aux évènements Gitlab (merge request ou comit) avant les déploiements en recette ou production.
Sentry : Monitoring de logs d’exécution

Sentry, en tant que logiciel de surveillance des applications et de suivi des erreurs, aide les développeurs à diagnostiquer, corriger et optimiser les performances de leur code de manière transparente. Avec cette solution, les développeurs peuvent découvrir le code source, filtrer les erreurs et empiler les locaux en temps réel, en plus d’améliorer la surveillance des performances de leur application avec des traces de pile. La solution comprend également des tableaux de bord pertinents qui ajoutent des éléments visuels à l’ensemble du système de surveillance des applications de manière transparente. Les utilisateurs peuvent utiliser la plateforme pour suivre les problèmes liés à un projet sélectionné et les corriger en cas d’erreur. Que les développeurs utilisent JavaScript, PHP ou tout autre langage, Sentry offre une visibilité précise des erreurs qui ont déjà été corrigées ainsi que de celles qui sont introduites pour la première fois. Pour créer le meilleur logiciel à tous points de vue, Sentry fournit un contexte précis, permet de découvrir des informations pour différentes équipes, y compris les ingénieurs, le support et les produits. Le logiciel permet également aux utilisateurs de rationaliser les notifications d’erreur dans leur boîte de réception.
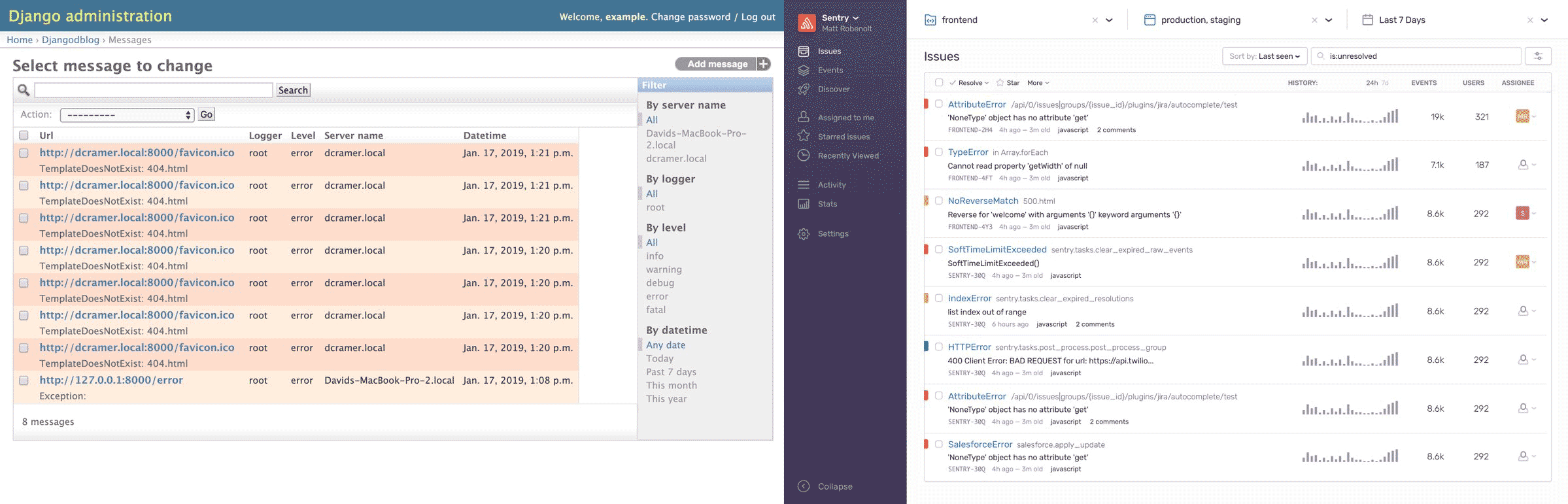
Sentry fournit un suivi des erreurs open source pour surveiller et corriger les bogues et les plantages n’importe où dans votre application en temps réel. Plus de développeurs utilisent Sentry que tout autre outil de suivi des erreurs pour améliorer l’efficacité des déploiements et garantir l’expérience utilisateur.
La fonction principale de Sentry est un système de surveillance en temps réel pour aider à corriger les erreurs et les plantages. La version améliorée de la plate-forme hébergée de cette application comprend davantage d’intégrations avec des services externes tels que GitHub et HipChat.
Grâce à cette solution, chaque développeur peut obtenir une perception immédiate de la manière dont son code de production affecte les utilisateurs réels et trace automatiquement les problèmes dans le cadre du flux de travail établi. Le tableau de bord de Sentry affiche les traces de la pile, avec la prise en charge des cartes source et la détection de l’URL de chaque erreur.
Sentry peut être intégré nativement au applications Symfony par le biais d’un package mis à disposition. Pour les autres types d’application, il convient de mettre en place une configuration spécifique en fonction de l’environnement applicatif.
Zabbix : Monitoring de santé des applications

Docker est sans doute l’un des outils DevOps les plus appréciés qui rationalise le développement, le déploiement et l’expédition d’applications dans des conteneurs.
La surveillance des conteneurs aide les équipes opérationnelles à identifier les problèmes sous-jacents et à les résoudre en temps opportun. La surveillance des conteneurs englobe la capture de métriques de base telles que les journaux en temps réel qui sont utiles pour déboguer et alerter l’équipe informatique lorsqu’il faut évoluer.
Zabbix est un outil de surveillance d’infrastructure informatique populaire qui surveille presque tous les éléments de votre environnement, y compris les périphériques physiques tels que les serveurs et les périphériques réseau tels que les routeurs et les commutateurs. Il peut également surveiller les applications, les services et les bases de données.
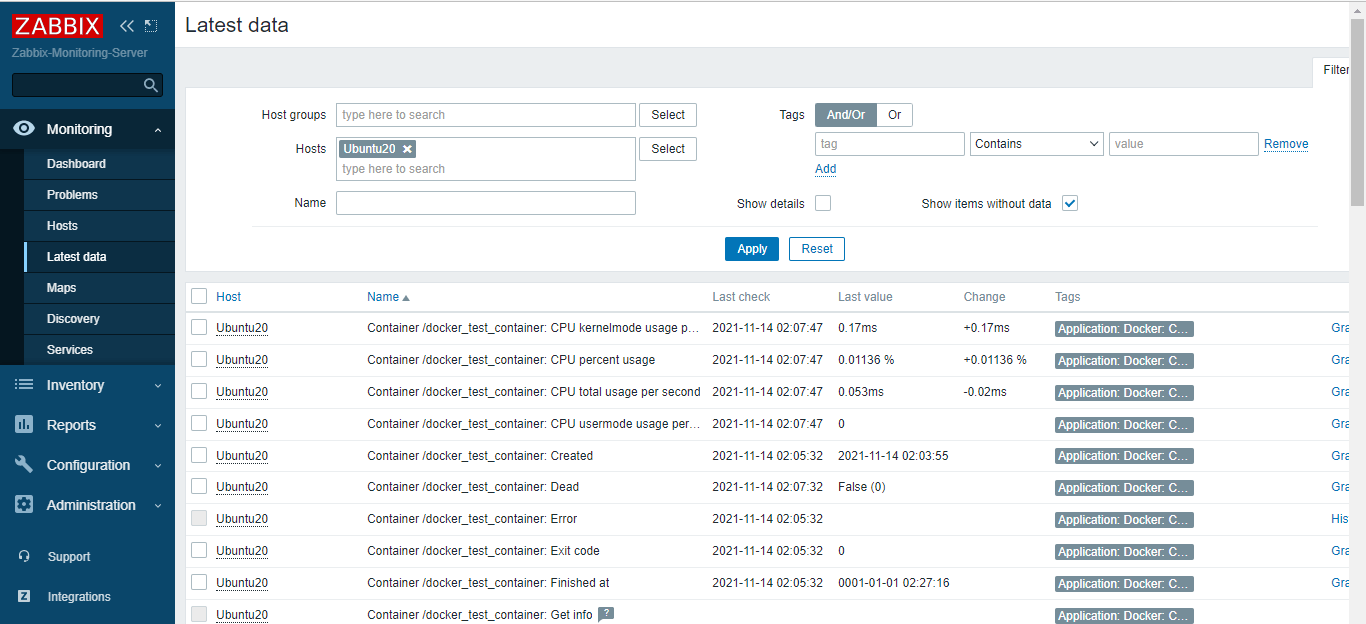
Un exemple d’implémentation de Zabbix pour Docker est disponible à cette adresse https://fr.linux-console.net/?p=2525
Grafana : Reporting global

Grafana est une plateforme open source, orientée observabilité, taillée pour la surveillance, l’analyse et la visualisation des métriques IT. Elle est livrée avec un serveur web (écrit en Go) permettant d’y accéder via une API HTTP. Sous licence Apache 2.02, Grafana génère ses graphiques et tableaux de bord à partir de bases de données de séries temporelles (time series database) telles que Graphite, InfluxDB ou OpenTSDB. Cette plateforme est aussi un outil indispensable pour créer des alertes.
Véritable éditeur de dashboards informatiques, Grafana permet également de les partager sous forme de snapshot (ou instantanés) avec d’autres utilisateurs. L’outil intègre par ailleurs un système de gestion des droits d’accès et protège les tableaux de bord des modifications accidentelles. Enfin, il bénéficie d’une application particulière pour Kubernetes. Baptisée Grafana App for Kubernetes, elle suit la performance des architectures applicatives basées sur l’orchestrateur open source via trois dashboards : cluster, node, pod/container et deployment.
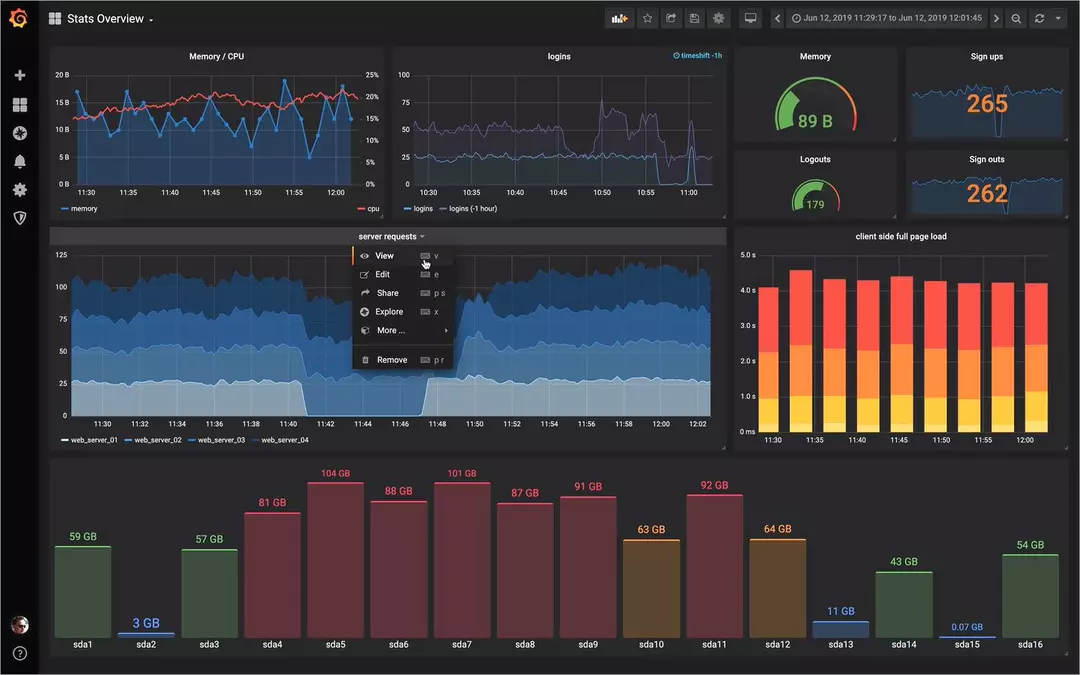
L’utilisation de Grafana permettrait d’intégrer les données issues des outils SonarQube, Sentry et Zabbix pour faire des dashboards pour affichage sur écran et des widget alertes en cas de problématiques.
Gestion des sources
L’installation de Gitlab sera faite par l’intermédiaire d’une image Docker mise à disposition par Gitlab (assurant son support lors des montées de version).
Gitlab SAAS to Gitlab OnPremise
Il faudra pour chaque projet faire l’import du dépôt. Une procédure au sein de l’installation de Gitlab permet de faciliter la migration des projets hébergés en SAAS vers l’instance onPremise (https://towardsdatascience.com/migrating-from-gitlab-saas-to-self-hosted-34b99bac0147).
Le système de miroring permet également de maintenir les 2 dépôts (SAAS et OnPremise) à jour pendant la période de transition (https://docs.gitlab.com/ee/user/project/repository/mirror/).
Il faudra bien veiller à mettre à jour les environnements de développement pour utiliser les nouveaux dépôts.
Subversion to Gitlab OnPremise
Il existe un processus de migration basé sur une synchronisation entre les dépôts Subversion et les dépôts Gitlab (https://docs.gitlab.cn/14.0/ee/user/project/import/svn.html). Cependant la migration necessite de revoir le processus de déploiement et de développement.
Déploiement
Applications Web : Gitlab CI/CD
Processus de développement
Le processus de développement sous Gitlab suit le principe d’utilisation des branches et des tags.
La branche principale correspond à la version actuellement en production. Son nom est généralement main ou master.
Lors d’un développement (lot de travail ou anomalie), on crée une nouvelle branche à partir de la branche principale et on initie une nouvelle version de travail collaborative. C’est sur cette branche que seront mise en place tous les développements. Certains travaux nécessitant une version de travail spécifique (fonctionnalité au sein d’un lot) peuvent donner lieu à la création d’une branche fonctionnelle à partir de la branche du lot. Une fois le travail réalisé, il est possible de créer un script CI/CD pour lancer le déploiement en test du code de façon automatisée. Le script peut également intégrer plusieurs environnements de test sur lesquels déployer.
Lors du déploiement en production, on peut procéder à une étape de validation de l’intégration. Si l’environnement dispose d’un serveur d’intégration spécifique à l’application, on peut simuler le déploiement en production dans un environnement dédié afin de s’assurer de son fonctionnement avec les données de production. Un script spécifique CI/CD peut être mis en place dans ce sens.
Une fois la validation de l’intégration, on procède à la mise en production. Pour se faire, on merge les modifications de la branche à déployer sur la branche principale puis on crée un tag. C’est ce tag qui peut être manuellement (ou automatiquement) déployé sur l’environnement de production dédié.
Une vidéo et un tutoriel sur le fonctionnement du Gitflow sont disponible à cette adresse https://grafikart.fr/tutoriels/git-flow-742
Infrastructure de déploiement
Il est possible de créer des environnements Docker à la volée pour le déploiement en production et en test.
Le processus de déploiement peut être défini comme suit :
- Demande d’utilisation d’un environnement Docker existant ou création d’un nouveau
- Sauvegarde des données de l’application
- Création d’une image Docker définie dans le fichier Dockerfile et intégration dans le référentiel Docker de Gitlab
- Suppression du (ou des) conteneurs Docker de l’application sur l’environnement cible
- Création du (ou des) conteneurs Docker de l’application sur l’environnement cible (possibilité d’utiliser le fichier docker-compose.yml)
- Lancement des actions de montée de version des données de l’application
Il sera nécessaire de créer un script de retour arrière en cas de problème constaté lors du déploiement intégrant la restauration des données sauvegardées.
Applications Delphi : FinalBuilder
Il est préférable de laisser le processus de création des livrables développés sous Delphi avec l’utilisation de Final Builder. Il est nécessaire en revanche de procéder à une réinstallation de l’environnement d’intégration sur un système d’exploitation plus récent afin de garantir la sécurité de l’environnement de déploiement.
Il serait intéressant cependant de porter les sources de développement Delphi sous Gitlab (actuellement sous Subversion) et d’expérimenter le lancement des scripts de construction et de déploiement pilotés par Gitlab CI/CD.
Applications Web PHP 4
Il est necessaire de revoir le mode d’exploitation (plate-forme de production et de test) ainsi que les modalités de déploiement des applications en PHP4. Il faut garantir le fonctionnement à travers un conteneur Docker maîtrisé, une image Docker maintenue et un environnement de déploiement dynamique.
La migration doit être réalisée en plusieurs étapes :
- Migration des sources sur GitLab
- Mise en place d’un environnement Docker de production basée sur une image extraite de l’application en production et avec des points de montages pour les données et fichiers
- Mise en place d’un système de sauvegarde de l’environnement pour la possibilité de retour arrière en cas de problème lors de la mise en production
- Mise en place d’un environnement Docker de test avec génération dynamique d’url (chargement dynamique du paramétrage)
- Mise en place d’un procéssus CI/CD pour les déploiements en test et en production
- Changement des IP pour les proxy